由于很多业务表因为历史原因或者性能原因,都使用了违反第一范式的设计模式。即同一个列中存储了多个属性值。 这种模式下,应用常常需要将这个列依据分隔符进行分割,并得到列转行的结果。 最近在做项目上的报表,写SQL是遇到逗号分隔字段的问题,不知道如何处理。 虽然是一个很low逼的问题,但还是花了不少时间,所以写个博客记录一下,顺便缅怀花费在此问题上的光阴。
问题描述
问题简单描述为库中有两张表a、b, a表如下:
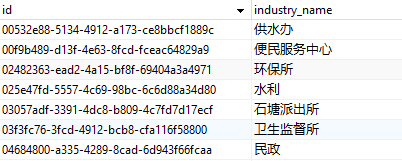
b表如下:

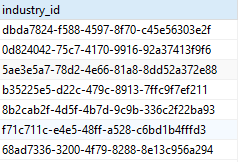
需要查询b表中industry_id字段所包含的所有a表id字段的记录。
期望结果:
方法一(FIND_IN_SET()函数)
MySQL手册中find_in_set函数的语法
FIND_IN_SET(str,strlist)
假如字符串str 在由N 子链组成的字符串列表strlist 中,则返回值的范围在 1 到 N 之间。 一个字符串列表就是一个由一些被 ‘,’ 符号分开的子链组成的字符串。如果第一个参数是一个常数字符串,而第二个是type SET列,则 FIND_IN_SET() 函数被优化,使用比特计算。 如果str不在strlist 或strlist 为空字符串,则返回值为 0 。如任意一个参数为NULL,则返回值为 NULL。这个函数在第一个参数包含一个逗号(‘,’)时将无法正常运行。
在我的实例中,我使用表关联加find_in_set函数,具体示例代码如下:
SELECT id
FROM a
JOIN b ON FIND_IN_SET(a.id,b.industry_id)
方法二(行列转换处理)
先来看具体SQL(基于问题描述中的a、b表):
SELECT substring_index(substring_index(b.industry_id,',',t_index.help_topic_id+1),',',-1)
FROM b
JOIN mysql.help_topic t_index
ON t_index.help_topic_id < (length(b.industry_id) - length(replace(b.industry_id,',',''))+1)
原理分析:
这个join最基本原理是笛卡尔积。通过这个方式来实现循环。 以下是具体问题分析: length(b.industry_id) - length(replace(b.industry_id,’,’,’’))+1 表示了,按照逗号分割后,改列拥有的数值数量,下面简称n JOIN过程的伪代码:
根据ID进行循环
{
判断:i 是否 <= n
{
获取最靠近第 i 个逗号之前的数据, 即 substring_index(substring_index(b.industry_id,',',t_index.ID),',',-1)
i = i +1
}
ID = ID +1
}
这种方法的缺点在于,我们需要一个拥有连续数列的独立表(这里是incre_table)。并且连续数列的最大值一定要大于符合分割的值的个数。 例如有一行的mSize 有100个逗号分割的值,那么我们的incre_table 就需要有至少100个连续行。 当然,mysql内部也有现成的连续数列表可用。如mysql.help_topic: help_topic_id 共有504个数值,一般能满足于大部分需求了。